
How to Extract Images from PDF Files Using Python
Read Time:4 Minute, 18 Second
In this comprehensive tutorial, the exciting world of image extraction from PDF files unfolds through the versatile Python programming language. The necessity to extract images from PDF files frequently arises, especially when handling various report types and documents. Manual execution of this task or reliance on existing software and online tools can prove to be laborious and time-intensive.
Throughout this tutorial, readers will embark on a journey to acquire the skills needed to automate the image extraction process from PDF files, harnessing the capabilities of the potent Python programming language. To effectively engage with this tutorial, two essential Python libraries, PyMuPDF and Pillow, will serve as indispensable tools.
In case you haven’t installed these libraries yet, please open the “Command Prompt” on Windows and execute the following code to ensure they are properly installed:
- pip install PyMuPDF;
- pip install Pillow.
Sample PDF Document
Let’s introduce the PDF file that will be the focus of this tutorial:
The PDF file we’ll be working with should be located in the same directory as our main.py code.
Additionally, it’s essential to create an empty folder named “images” to store the images we’ll extract. Consequently, your project directory structure should resemble the following:
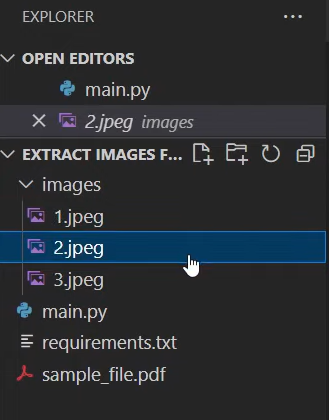
Extracting Images from PDFs with Python
We’ll initiate our journey by importing the necessary dependencies:
#Import required dependencies
import fitz
import os
from PIL import Image
Specify the PDF file path:
#Define path to PDF file
file_path = 'sample_file.pdf'
Open the file using the "fitz" module and retrieve information about all the images:
#Open PDF file
pdf_file = fitz.open(file_path)
#Calculate number of pages in PDF file
page_nums = len(pdf_file)
#Create empty list to store images information
images_list = []
#Extract all images information from each page
for page_num in range(page_nums):
page_content = pdf_file[page_num]
images_list.extend(page_content.get_images())Now, let’s examine the information we’ve extracted regarding the images:
print(images_list)
You should receive the following:
- [(9, 0, 640, 491, 8, ‘DeviceRGB’, ”, ‘Image9’, ‘DCTDecode’);
- (10, 0, 640, 427, 8, ‘DeviceRGB’, ”, ‘Image10’, ‘DCTDecode’);
- (13, 0, 640, 427, 8, ‘DeviceRGB’, ”, ‘Image13’, ‘DCTDecode’)].
Each tuple corresponds to the following:
- (xref, smask, width, height, bpc, colorspace, alt. colorspace, name, filter)
Now, we’ll incorporate error-handling code to handle cases where the PDF file we’re processing contains no images:
#Raise error if PDF has no images
if len(images_list)==0:
raise ValueError(f'No images found in {file_path}')Once we’ve retrieved the image information from the PDF file, we can proceed to extract the actual images and store them on your computer:
#Save all the extracted images
for i, image in enumerate(images_list, start=1):
#Extract the image object number
xref = image[0]
#Extract image
base_image = pdf_file.extract_image(xref)
#Store image bytes
image_bytes = base_image['image']
#Store image extension
image_ext = base_image['ext']
#Generate image file name
image_name = str(i) + '.' + image_ext
#Save image
with open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()Upon executing the code, you will witness the extracted images gracefully manifest within the designated “images” directory, making your PDF image extraction endeavor visibly fruitful.
Complete code
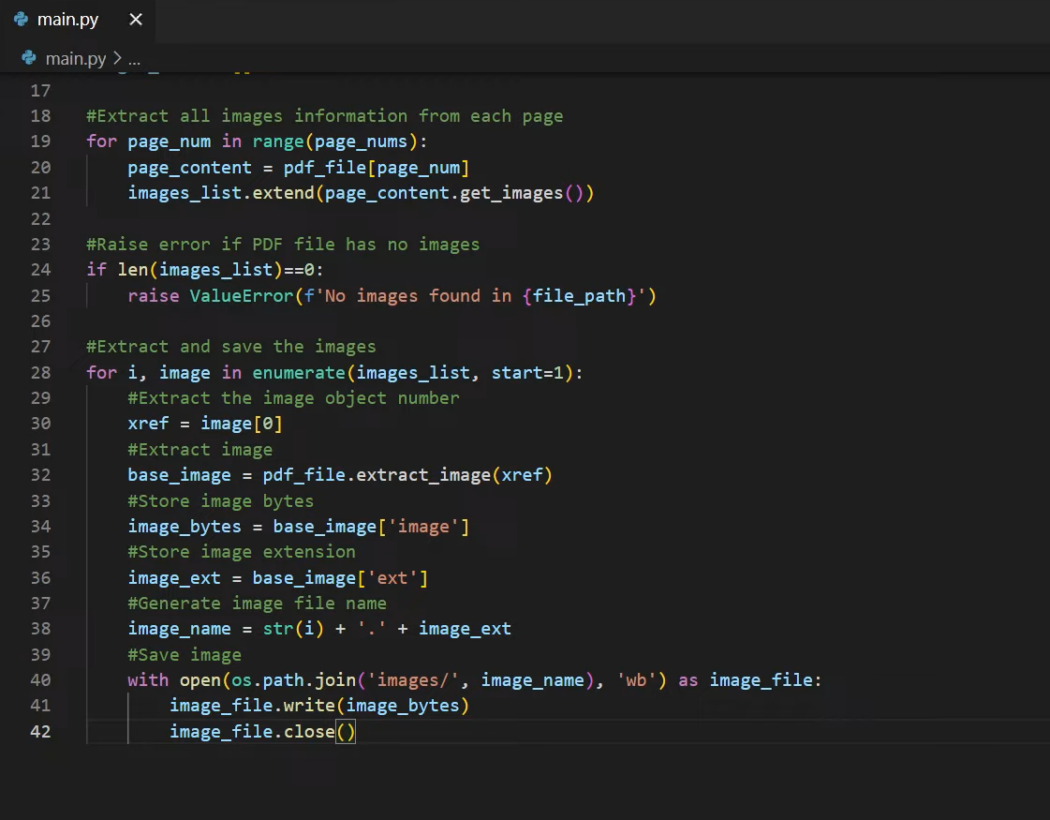
#Import required dependencies
import fitz
import os
from PIL import Image
#Define path to PDF file
file_path = 'sample_file.pdf'
#Define path for saved images
images_path = 'images/'
#Open PDF file
pdf_file = fitz.open(file_path)
#Get the number of pages in PDF file
page_nums = len(pdf_file)
#Create empty list to store images information
images_list = []
#Extract all images information from each page
for page_num in range(page_nums):
page_content = pdf_file[page_num]
images_list.extend(page_content.get_images())
#Raise error if PDF has no images
if len(images_list)==0:
raise ValueError(f'No images found in {file_path}')
#Save all the extracted images
for i, img in enumerate(images_list, start=1):
#Extract the image object number
xref = img[0]
#Extract image
base_image = pdf_file.extract_image(xref)
#Store image bytes
image_bytes = base_image['image']
#Store image extension
image_ext = base_image['ext']
#Generate image file name
image_name = str(i) + '.' + image_ext
#Save image
with open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()Conclusion
In this comprehensive article, we’ve explored the realm of PDF image extraction, capitalizing on Python’s prowess, coupled with the PyMuPDF library. This journey delves into the intricacies of this process, encompassing vital elements like opening PDF files, extracting image data, and the final step of preserving those extracted images on your system. With this newfound proficiency, readers are now armed to confidently navigate the complex landscape of PDF image extraction, paving the way for enhanced productivity. As you further delve into Python’s versatile capabilities, remember that extracting images from PDFs is just one of its many intriguing achievements.
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %
Average Rating