Mastering Jaccard Coefficients and Distances with Python
Read Time:4 Minute, 24 Second
Understanding Jaccard coefficients and their corresponding distances is essential for anyone engaged in data science, machine learning, or NLP projects. Especially when employing Python, these mathematical models can greatly help in calculating the likeness or disparity between two sets.
This guide will elucidate the intricacies of using these calculations within Python for various applications, including their utility, code execution, and best practices.
Importance of Jaccard Coefficients
The Jaccard coefficient, also commonly referred to as the Jaccard index or Jaccard similarity score, has become an indispensable tool in the analysis of data relationships. The applications of this metric are vast and varied, making it a cornerstone in numerous industries. Here’s an in-depth look at some of the sectors where the Jaccard coefficient is widely used:
- Text Mining: When it comes to natural language processing (NLP) and text analytics, Jaccard coefficients can measure the semantic similarity between two documents or sets of terms;
- Cluster Analysis: In data clustering, the Jaccard index helps in identifying the most related groups of data points, thereby informing better data modeling approaches;
- Recommender Systems: For e-commerce platforms and media streaming services, the Jaccard index aids in tailoring user-specific recommendations based on their preferences;
- Search Engines: Search algorithms often employ Jaccard coefficients to enhance the relevance and quality of search results, leading to an improved user experience.
Conceptual Overview
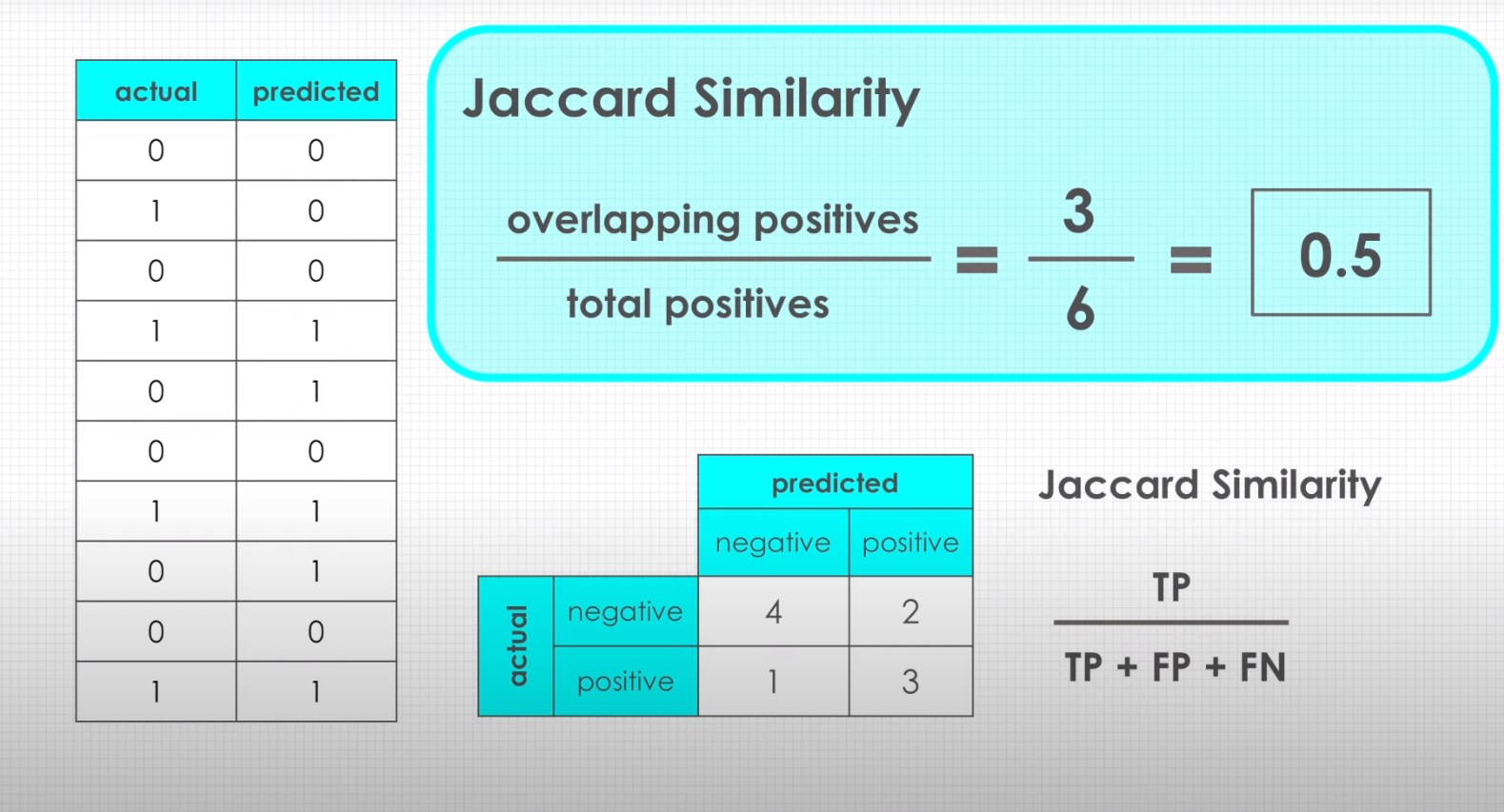
The Jaccard coefficient is rooted in set theory. It offers a mathematical approach to gauge the similarity between two sets by taking into account both their intersection and their union. The result is a ratio that ranges from 0 to 1, where a score closer to 1 indicates a higher degree of similarity between the sets. It is computed using the formula:
Jaccard Index=∣�∩�∣∣�∪�∣
Jaccard Index=
∣A∪B∣
∣A∩B∣
Here,
∣A∩B∣
∣A∩B∣ represents the size of the intersection of sets A and B, while
∣A∪B∣
∣A∪B∣ represents the size of the union of those sets.
Python Libraries for Jaccard Calculations
Calculating the Jaccard index within Python has been made easier thanks to a plethora of specialized libraries. Here are some popular options:
- Scikit-learn: Widely used for machine learning tasks, it provides built-in functions for Jaccard similarity computations;
- SciPy: This library offers an extensive suite of mathematical tools, including utilities for calculating set-based metrics;
- NLTK (Natural Language Toolkit): Particularly useful for NLP projects, NLTK includes text processing libraries that allow easy calculation of Jaccard coefficients.
Calculating Jaccard Coefficients in Python
Executing the Jaccard index in Python follows a straightforward workflow. Here are the typical steps:
- Import Libraries: Start by importing the essential libraries, whether that’s Scikit-learn, SciPy, or others;
- Data Preparation: The next step is to prepare the data sets. The data can come from various sources, and proper preprocessing is essential to ensure accurate calculations;
- Algorithm Implementation: Lastly, you will either call pre-defined functions from the imported libraries or define a custom function to calculate the Jaccard index. Most of the time, the function call will be sufficient for most needs.
Practical Use-Cases of Jaccard Distance
Jaccard distance serves as the complementary counterpart to the Jaccard index. While the index measures similarity, the distance metric gauges dissimilarity. It’s instrumental in several applications:
- Anomaly Detection: For flagging unusual patterns in data, thus alerting to potential issues;
- Fraud Detection: Used in financial sectors to identify fraudulent activities by measuring dissimilarity in transaction patterns;
- Image Recognition: A crucial tool for differentiating between various types of images based on their feature sets.
Implementing Jaccard Distance in Python
Creating Jaccard distance computations in Python is almost identical to working with the Jaccard index. The core components of this task include:
- Library Import: Import the libraries that offer Jaccard distance functionalities;
- Data Setup: Prepare the data sets to be used in the calculation. This could involve data cleaning and formatting steps;
- Calculation: Either use the existing Python functions or define a new function for Jaccard distance computation.
Performance Metrics
Evaluating the efficiency and effectiveness of Jaccard calculations in Python involves:
- Computation Time: Measuring the time it takes for the code to execute can offer insights into its efficiency;
- Resource Utilization: Assess the computational resources used, such as CPU and memory, to ensure optimal performance.
Handling Sparse Data
Sparse data sets are common in large data projects. Special libraries like scikit-learn offer sparse matrix functionalities that enable efficient calculations without compromising on memory.
Troubleshooting Common Errors
Common pitfalls in Jaccard computations may relate to:
- Data Quality: Poor data quality can severely affect the results;
- Library Conflicts: Ensure that the chosen Python libraries are compatible with each other.
Advanced Topics
Advanced areas of interest may include:
- Jaccard-based Clustering: An innovative way of cluster analysis that involves Jaccard metrics;
- Deep Learning Applications: The use of Jaccard indices in neural networks and other advanced machine learning models.
Conclusion
The utility of Jaccard coefficients and distances in Python covers a broad range of applications, from text mining and search engine optimization to complex machine learning algorithms.
Understanding how to implement these computations efficiently in Python is vital for anyone working with data sets. This guide aims to offer a well-rounded perspective on executing Jaccard calculations effectively in Python, regardless of one’s level of expertise.
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %

Average Rating