An In-Depth Look at VectorAssembler in PySpark
Read Time:2 Minute, 49 Second
This article delves into the world of feature engineering using PySpark’s VectorAssembler, providing an in-depth understanding of the process and its applications.
In the realm of Python, particularly when working with libraries like scikit-learn, many models accept raw DataFrames as input for training. However, when operating in a distributed environment, the process becomes more intricate, necessitating the use of Assemblers to prepare our training data.
Within the Spark ML library, the VectorAssembler module offers a solution for converting numerical features into a consolidated vector. This vector, known as the feature vector, serves as input for machine learning models.
To provide an overview, VectorAssembler takes a list of columns (features) and merges them into a single vector column (the feature vector). This consolidated vector subsequently serves as input for machine learning models within the Spark ML framework.
To follow this tutorial, it is essential to have Spark and Java installed on your machine, along with the following Python library: pyspark.
- pip install pyspark.
Establishing a SparkSession using PySpark
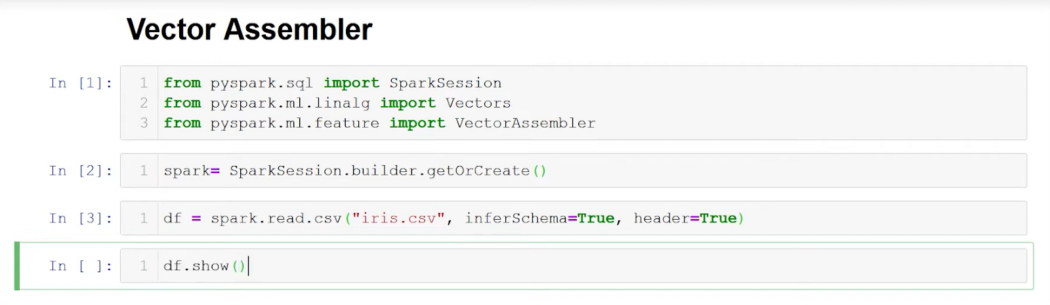
The initial and primary entry point for accessing all Spark capabilities is through the SparkSession class:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('mysession').getOrCreate()Generating a Spark DataFrame using PySpark
In the subsequent stage, we’ll generate a basic Spark DataFrame consisting of three features (“Age,” “Experience,” “Education”) and a target variable (“Salary”).
df = spark.createDataFrame(
[
(20, 1, 2, 22000),
(25, 2, 3, 30000),
(36, 12, 6, 70000),
],
["Age", "Experience", "Education", "Salary"]
)Now, let’s examine it:
df.show()| Age | Experience | Education | Salary |
|---|---|---|---|
| 20 | 1 | 2 | 22000 |
| 25 | 2 | 3 | 30000 |
| 36 | 12 | 6 | 70000 |
In this instance, the DataFrame exhibits simplicity, containing solely numerical data. However, when engaging in projects involving different datasets, it is imperative to accurately discern and convert data types, scrutinize for any missing values, and undertake the necessary data manipulations.
Combining Numeric Features into a Vector Column in PySpark
In this step, our objective is to merge three numerical features, namely “Age,” “Experience,” and “Education,” into a unified vector column that we’ll conveniently name “features.”
To achieve this, you can utilize the VectorAssembler in PySpark, which involves specifying two essential parameters:
- ‘inputCols’ – This parameter necessitates a list of the features intended to be merged into a single vector column;
- ‘outputCol’ – Here, the name of the newly created column that will hold the transformed vector is specified.
Let’s proceed to create our VectorAssembler for this purpose:
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=["Age", "Experience", "Education"],
outputCol="features")Using this assembler, the original dataset can be transformed, and the resulting outcome can be observed.
output = assembler.transform(df)
output.show()
+---+----------+---------+------+---------------+
|Age|Experience|Education|Salary| features|
+---+----------+---------+------+---------------+
| 20| 1| 2| 22000| [20.0,1.0,2.0]|
| 25| 2| 3| 30000| [25.0,2.0,3.0]|
| 36| 12| 6| 70000|[36.0,12.0,6.0]|
+---+----------+---------+------+---------------+Great! You can now utilize this DataFrame to train Spark ML models by using the “features” vector column as your input variable and “salary” as your target variable.
Conclusion
This article delved into the powerful technique of feature engineering in PySpark, leveraging the VectorAssembler for creating composite feature vectors.
If you found this exploration intriguing, I invite you to explore my other articles on the topic of Feature Engineering. Expanding your knowledge in this area can greatly enhance your ability to extract valuable insights and build robust machine learning models.
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %


Average Rating