
Download PDF from URL using Python: A Guide
Read Time:2 Minute, 59 Second
In today’s digital age, the ability to extract and manipulate data from the web is a valuable skill. This guide will walk you through the process of downloading PDF files from URLs using Python. Whether you’re a data enthusiast, researcher, or developer, this skill can come in handy in various scenarios.
Getting Started
To embark on this journey, you’ll need a few tools and libraries at your disposal. Let’s set the stage before diving into the actual code.
Setting up Your Environment
Before you begin, make sure you have Python installed on your system. If not, head over to the Python website to download and install the latest version.
Installing Necessary Libraries
Python offers a wealth of libraries, and for this task, we’ll primarily rely on the following:
- Requests: This library will help us fetch the content of the URL;
- Beautiful Soup: We’ll use this library for parsing HTML and extracting the PDF URLs;
- Urllib: This library aids in downloading files from URLs.
To install these libraries, open your command prompt or terminal and use the following commands:

Understanding the Process
Before we jump into coding, it’s essential to understand the steps involved in downloading a PDF file from a URL using Python.
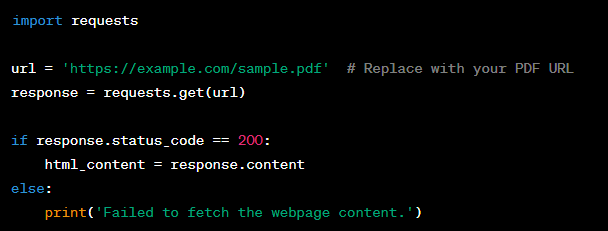
- Fetch the Webpage Content: We’ll use the requests library to retrieve the HTML content of the webpage;
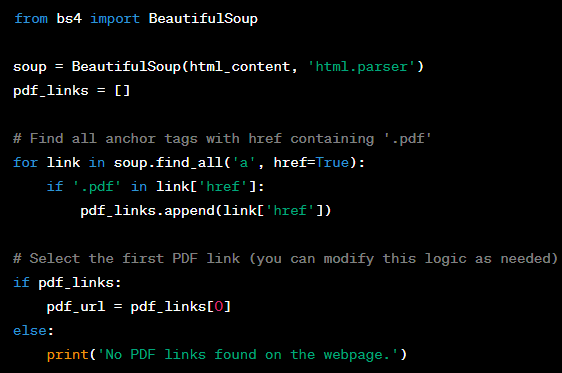
- Parse HTML: With the help of Beautiful Soup, we’ll parse the HTML content to locate the PDF file’s URL;
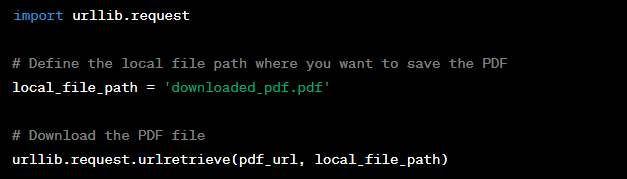
- Download the PDF: Finally, we’ll use the urllib library to download the PDF file from the URL.
Coding the Solution
Now that we have a clear understanding, let’s get down to coding.
Step 1: Fetch the Webpage Content
Step 2: Parse HTML to Extract PDF URL
Step 3: Download the PDF
Tips and Best Practices
- Error Handling: Implement robust error handling to account for various scenarios, such as invalid URLs or network issues;
- Security: Ensure that you have the necessary permissions to access and download content from the provided URL;
- Automation: Consider automating this process for multiple URLs or scheduling downloads as needed.
Conclusion
In this comprehensive guide, you’ve learned how to download PDF files from URLs using Python. This skill can be incredibly useful in various fields, from data analysis to web scraping. By following the steps outlined here and customizing the code to your specific needs, you can harness the power of Python to simplify the process of retrieving PDFs from the web.
FAQs
1. Can I use this method to download PDFs from any website?
While this method works for many websites, some may have measures in place to prevent automated downloads. Always respect website terms of service and use this responsibly.
2. How can I download multiple PDFs in one go?
You can automate the process by creating a script that iterates through a list of URLs and downloads each PDF sequentially.
3. Is Python the only language I can use for this task?
No, you can achieve similar results with other programming languages, but Python is known for its simplicity and powerful libraries, making it a popular choice for web-related tasks.
4. Are there any legal considerations when downloading content from the web?
Yes, downloading copyrighted material without permission may infringe on intellectual property rights. Always ensure you have the right to access and download the content.
5. What if the PDF link is generated dynamically on the webpage?
In such cases, you may need to inspect the webpage’s source code and understand how the PDF links are generated. Your parsing logic would then need to adapt accordingly.
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %


Average Rating