Unlocking Tables in HTML: Retrieving Tabular Data
Read Time:7 Minute, 23 Second
In the digital age, information is abundant, but often locked within the confines of HTML documents. As data-driven decision-making becomes increasingly vital, the ability to liberate structured information from web pages has become a valuable skill. In this tutorial, we embark on an exploration of how to harness the power of Python to extract tables from HTML files. Whether you’re a data scientist seeking to automate data collection, a web developer aiming to streamline content extraction, or simply curious about the inner workings of web scraping, this guide will equip you with the knowledge and tools to efficiently extract tabular data from these documents. Join us on this journey as we unravel the secrets of this table extraction and empower you to unleash the data hidden within web pages.
The Significance of Extracting Tables from Digital Content
In the vast digital realm, tables represent a structured and organized format for data representation. Quite often, while browsing websites or working with HTML files, one may come across valuable tabular data that needs to be preserved or analyzed. Think of those times when you spotted an essential data set on a website, and wished to analyze it for a project or integrate it into a report.
However, the traditional methods of manually copying and pasting can become quite cumbersome. This process not only consumes an unnecessary amount of time but also poses challenges in retaining the original structure and formatting of the table.
Leveraging Python for Tabular Data Extraction
Fortunately, with the evolution of programming, automating such tasks has become possible. Python, one of the most versatile programming languages, offers a suite of libraries that can efficiently handle, extract, and process data from web pages and HTML files.
Some of the notable benefits of using Python for this purpose include:
- Automation: Say goodbye to tedious manual extraction;
- Accuracy: Ensures that data is captured precisely without missing values;
- Preservation of Structure: Maintains the original layout and formatting of tables;
- Versatility: Easily integrates with other tools and platforms for further analysis or visualization.
Essential Python Libraries for Data Extraction
For those keen on exploring this avenue, three primary Python libraries come to the rescue:
- pandas: Renowned for data manipulation and analysis, pandas makes working with structured data a breeze;
- html5lib: A pure-Python library for parsing HTML, it’s ideal for working with web content;
- lxml: A library that provides a way to parse XML and HTML documents swiftly and efficiently.
Getting Started: Installing the Necessary Libraries
If the journey of data extraction intrigues you, begin by setting up the required environment. For those working on a Windows platform, the Command Prompt serves as the starting point.
Follow these steps to install the necessary libraries:
Launch the Command Prompt on your Windows system.
To install pandas, input the following command:
pip install pandasFor html5lib, use:
pip install html5libLastly, to equip your environment with lxml, execute:
pip install lxmlTips for a Smooth Installation Process:
- Ensure you have the latest version of pip installed;
- If facing issues, consider using a virtual environment for a clean setup;
- Always refer to the official documentation of each library for any troubleshooting or advanced installation options.
Acquiring a Sample HTML File with Table Data
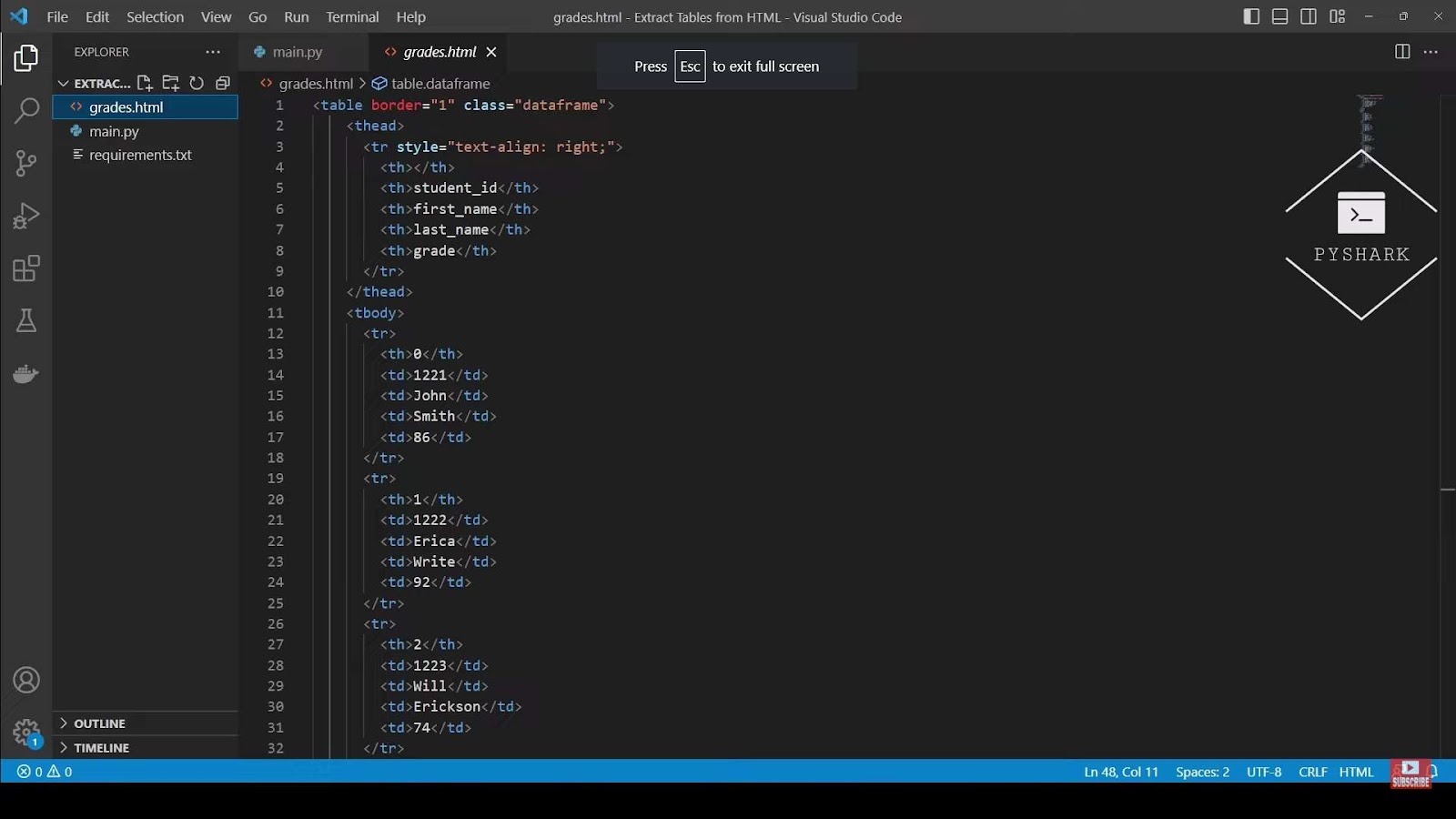
With all necessary tools in place, it’s time to take a closer look at an HTML file that houses table data. For this illustration, we will utilize an example, which was constructed in a past lesson. Named as gradesDownload, this file encloses the subsequent code:
<table border="1" class="dataframe">
<!--... rest of the table structure ...-->
</table>When this file is launched in a standard web browser, viewers will observe data neatly presented in a tabular layout. It’s advisable to ensure the file is stored within the identical directory as your Python script for seamless access.
It’s worth noting that this file exclusively comprises code for this single table. Nevertheless, the techniques and scripts showcased in the ensuing sections are versatile and can seamlessly handle documents brimming with multiple tables and diverse elements.
Extracting Table Content
The succeeding segment elucidates the method to harness Python in extracting table contents from an HTML file.
To kick things off, there’s a need to incorporate the indispensable library and stipulate the location of this:
# Incorporate the necessary library
import pandas as pd
# Specify the HTML file's location
html_path = 'grades.html'Subsequently, the read_html() function from the Pandas library is summoned to retrieve tables from the file. These tables are then stored in a collection of DataFrames. For clarity, every table will be displayed with a gap in between:
# Extract tables from the specified HTML file
tables = pd.read_html(html_path)
# Showcase each table, punctuated by blank lines for clarity
for table in tables:
print(table, '\n\n')When the above Python script is executed, the output should resemble:
Unnamed: 0 student_id first_name last_name grade
0 0 1221 John Smith 86
1 1 1222 Erica Write 92
2 2 1223 Will Erickson 74
3 3 1224 Madeline Berg 82
4 4 1225 Mike Ellis 79
In scenarios where the extracted tables necessitate saving for future reference or processing, there’s the flexibility to export them into a CSV format. A point of importance is that if the source HTML is populated with several tables, the script will capture and display each one.
Webpage Table Extraction with Python
Extracting data tables from websites can be a vital step for data analysis. Python offers tools that make this process straightforward and efficient. Here’s a comprehensive guide to extracting tables from a webpage using Python:
1. Setting the Stage
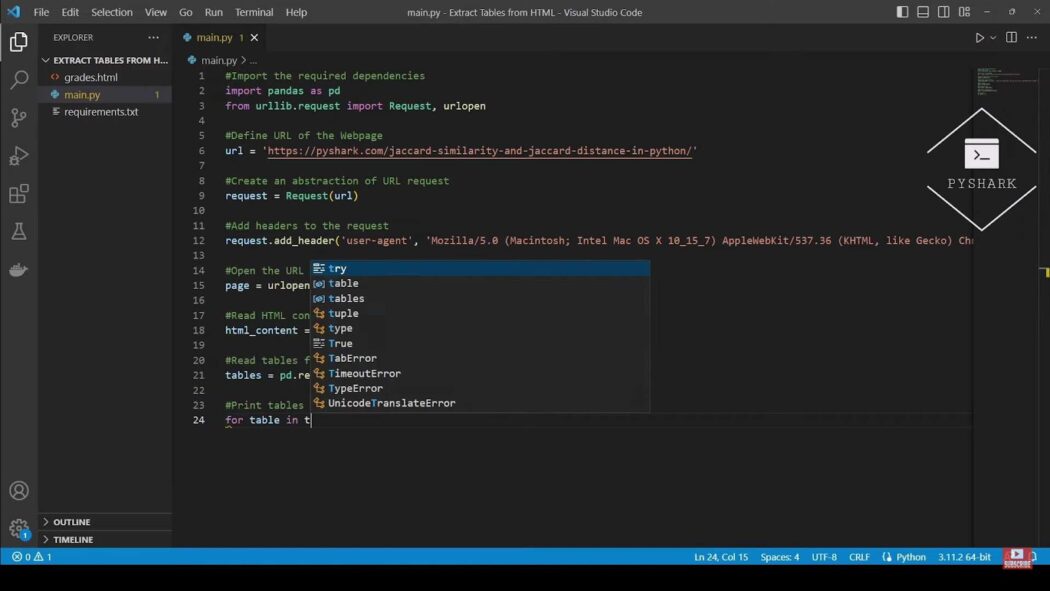
To begin, ensure that the essential libraries are imported and specify the webpage’s URL from which the tables are to be extracted.
# Import the necessary libraries
import pandas as pd
from urllib.request import Request, urlopen
# Specify the webpage URL
url = 'https://pyshark.com/jaccard-similarity-and-jaccard-distance-in-python/'In this scenario, the focus is on extracting tables from an article related to the Jaccard similarity and Jaccard distance concepts in Python. This article interestingly contains three distinct tables for extraction.
2. Fetching the Webpage Content
To retrieve the content from the specified webpage, utilize the urllib library:
# Construct a request object
request = Request(url)
# Incorporate headers to the request for compatibility
request.add_header('user-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36')
# Open and read the webpage content
page = urlopen(request)
html_content = page.read()3. Table Extraction from the HTML Content
With the help of the pandas library, it’s possible to read and process tables from the HTML content:
# Extract tables into a list of DataFrames
tables = pd.read_html(html_content)
# Display the extracted tables
for table in tables:
print(table, '\n\n')When the code runs successfully, the expected output will be the tables present in the webpage, which might look similar to:
0 1 2 3 4 5 6
0 NaN Apple Tomato Eggs Milk Coffee Sugar
…
4. Conversion of HTML Tables to CSV Format
After extracting the tables, they can be further processed or stored for future use. One common storage format is CSV (Comma-Separated Values).
To save the tables in CSV format, modify the earlier loop:
# Save the extracted tables as CSV files
for i, table in enumerate(tables, start=1):
file_name = f'table_{i}.csv'
table.to_csv(file_name)Upon execution, individual CSV files corresponding to each extracted table will be generated in the directory containing the Python script.
In conclusion, Python offers an efficient and streamlined method to extract and store tables from webpages, making it a powerful tool for data analysts and enthusiasts alike.
Conclusion
In this informative piece, we delve into the art of table extraction from HTML documents and webpages, employing the dynamic trio of Python, pandas, and urllib. Should you find yourself in need of further clarification or wish to contribute your insights through constructive comments, please do not hesitate to engage with us below. Your questions and suggestions are most welcome.
Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %

Average Rating